Google I/O 2024:开启新一代的 I/O



编者按:以下是 Sundar Pichai 在 2024 年 I/O 大会上讲话编辑稿,经过调整以包含更多在舞台上宣布的内容。
Google 已全面进入 Gemini 时代。
在深入探讨之前,我想先回顾一下我们所处的时刻。十多年来,我们一直在 AI 领域进行投入,并在各个层面进行创新:研究、产品、基础设施,今天我们将对此进行全面讨论。
尽管如此,我们仍处于 AI 平台转型的初期。我们看到了为创作者、开发者、初创公司以及每一个人所带来的巨大机遇。帮助推动这些机遇正是我们 Gemini 时代的意义所在。让我们开始吧。
Gemini 时代
一年前,在 I/O 大会上,我们首次分享了 Gemini 的计划:一个从一开始就构建为原生多模态的前沿模型,能够跨文本、图像、视频、代码等多种数据类型进行推理。它标志着将任意输入转换成任意输出的重要一步——新一代的“I/O”。
自那以来,我们推出了首批 Gemini 模型,这是我们迄今为止功能最强大的模型。它们在每个多模态基准测试中都拥有卓越的表现。两个月后,我们又推出了 Gemini 1.5 Pro,它在处理长上下文方面取得了重大突破,能够稳定地在生产环境中运行 100 万个令牌(Token),比目前任何其他大规模基础模型都要多。
我们希望每个人都能从 Gemini 的功能中受益。因此,我们立即行动起来,与大家分享这些进展。目前,超过 150 万的开发者在使用我们各种工具中的 Gemini 模型。你们使用它来调试代码、获得新的见解并打造下一代的 AI 应用。
我们也在不断将 Gemini 的突破性功能以强大的方式整合到我们的产品中。今天,我们将展示搜索、Photos、Workspace 和 Android 等产品中的实例。
产品进展
今天,我们所有拥有 20 亿用户的产品都在使用 Gemini。
我们还推出了全新的体验,包括在移动设备上,人们现在可以通过 Android 和 iOS 上的应用程序直接与 Gemini 互动, Gemini Advanced让用户还可以使用我们功能最强的模型。仅在三个月的时间里,已有超过一百万人注册试用,并且势头依然强劲。
在搜索中扩展 AI Overviews
Gemini 带来的最令人兴奋的变革之一是在 Google 搜索中。
在过去的一年中,作为我们生成式搜索体验(Search Generative Experience)的一部分,我们已经回答了数十亿个搜索查询。人们正在以全新的方式使用搜索,提出全新类型的问题,作出更长、更复杂的查询,甚至是通过照片进行搜索,并获得网络上的最佳信息。

我们一直在 Labs 之外对这种体验进行测试。我们倍受鼓舞地看到,不仅搜索的使用量有所增加,用户满意度也得到了提升。
我很高兴宣布,我们将于本周在美国向所有用户推出这一全新改版的 AI Overviews 体验。我们很快也将把这项体验推广到更多国家。
在搜索领域正发生着诸多创新。得益于 Gemini,我们能够打造更为强大的搜索体验,包括在我们的产品之中。
介绍 Ask Photos
Google Photos 就是一个例子,在大约九年前,我们发布了这款产品,自那以来,人们一直用它来整理最珍贵的回忆。如今,每天上传的照片和视频数量超过 60 亿。
人们喜欢使用 Photos 来搜索他们生活中的点滴。借助 Gemini,我们让这一切变得更加简单。
假设你在停车场缴费时,却想不起自己的车牌号。以往,你需要在 Photos 中搜索关键词,然后翻找多年积累的照片来寻找车牌。但现在,你只需直接询问 Photos 即可。它能够识别出经常出现的车辆,通过多方信息交叉验证判断出哪一辆是你的,并提供车牌号码。
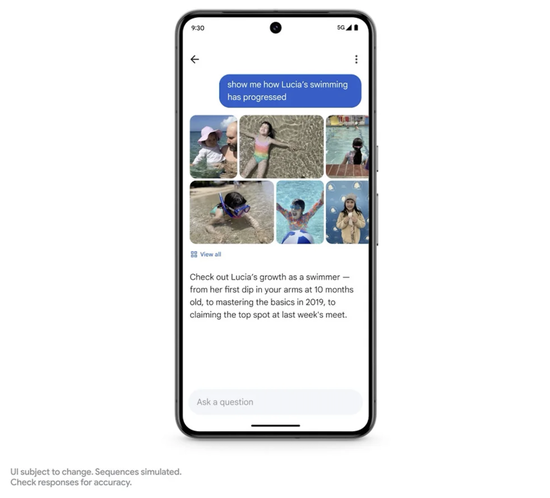
Ask Photos 还能够帮助你以更深入的方式重温回忆。例如,你可能正在回味女儿 Lucia 成长的早期重要时刻。现在,你可以直接问 Photos:“Lucia 是什么时候学会游泳的?”
你甚至可以跟进提出更复杂的问题:“向我展示 Lucia 的游泳技能是怎么进步的。”
在这里,Gemini 不再只是进行简单的搜索,它会识别不同的上下文——从在游泳池中扑腾,到在海洋中浮潜,再到她游泳证书上的文字和日期。Photos 会将所有这些信息整合在一起形成一个总结,让你能够全面了解,并再次重温那些美妙的回忆。我们将在今年夏天推出 Ask Photos,并将持续增加更多功能。
通过多模态和长上下文解锁更多知识
为了理解跨越不同格式的各种知识,我们从一开始就将Gemini 打造成多模态的。它是一个内置了所有模态的模型。因此,它可以理解不同类型的输入,并找到它们之间的联系。
多模态从根本上扩展了我们可以提出的问题以及我们将得到的答案。而长文本能力则使其更进一步,让我们能够引入更多信息:数百页文本、数小时音频或一小时的视频、整个代码存储库……或者,如果你愿意,大约 96 份芝士蛋糕工厂餐厅的菜单。
处理这么大量的菜单,你可能需要 100 万令牌的上下文窗口,而现在通过 Gemini 1.5 Pro 就可以实现。开发者们就一直在以各种非常有趣的方式使用它。
在过去的几个月里,我们已经推出了具有长上下文能力的 Gemini 1.5 Pro的预览版,我们还对翻译、编码和推理的质量进行了一系列改进。从今天开始,你也将在模型中看到这些更新。
现在我很高兴地宣布,我们将向全球所有开发者推出改进版的 Gemini 1.5 Pro。此外,从今天开始,具有100 万令牌上下文能力的 Gemini 1.5 Pro 也可供 Gemini Advanced 的消费者直接使用,包含 35 种语言。
在非公开预览版中扩展到 200 万令牌
100 万令牌正在开辟全新的可能性。这已经很振奋人心,但我认为我们还可以更进一步。
今天,我们将上下文窗口扩展到 200 万个令牌,并将其以非公开预览版的方式提供给开发者们。
过去几个月来我们所取得的进展让我非常激动,这代表着我们朝无限上下文的最终目标又迈出了一步。
将 Gemini 1.5 Pro 应用于 Workspace
到目前为止,我们已经分享了两项技术进步:多模态和长上下文。他们各自已经非常强大,但二者结合能够释放更深层次的能力和更多的智能。
这在 Google Workspace 中体现得更加淋漓尽致。
长期以来,人们总在 Gmail 中搜索他们的电子邮件。而现在我们正通过 Gemini 使其变得更加强大。例如,作为家长,你希望随时了解孩子在学校发生的一切,Gemini 就可以帮助你!
现在,我们可以让 Gemini 总结学校最近发来的所有电子邮件。在后台,它可以识别相关电子邮件,甚至分析 PDF 等附件,你可以获得一份包含关键要点和待办事项的摘要。也许你本周正在旅途中,无法参加家长会议,而会议录音长达一个小时。如果这份录音来自于 Google Meet,你就可以让 Gemini 为你提供重点内容。倘若有个家长小组正在寻找志愿者,而你那天正好有空,那么当然,Gemini 还可以帮助你起草回复邮件。
还有无数其他例子可以说明 Gemini 如何让生活更轻松。今天起 Gemini 1.5 Pro 已经应用在 Workspace Labs 中。
NotebookLM 中的音频输出
我们刚刚看了一个文本输出的例子,但通过多模态模型,我们可以做得更多。
我们在这方面已经取得了进展,未来还会有更多。NotebookLM 中的音频概述(Audio Overview)就显示了在这方面的进展:它通过 Gemini 1.5 Pro,可以基于你的源文件生成个性化和交互式音频对话。
这就是多模态带来的可能性,很快你就能够将输入和输出进行混合和匹配,这就是我们所说的新一代 I/O的意思。但如果我们还能再进一步呢?
使用 AI 智能体更进一步
在这一方面更进一步就是我们在 AI 智能体(AI Agents)上看到的机遇之一。我认为它们是可以推理、规划和记忆的智能系统。它们能够提前多步”思考”,跨软件和系统工作,所有这些都是为了帮助你完成任务,而最重要的是要在你的监督之下。
我们仍处于早期阶段,但让我向你展示一些我们正在努力解决的应用案例的类型。
让我们以购物为例。买鞋很有意思,但当鞋子不合适需要退货时就不那么有趣了。
想象一下,如果 Gemini 可以为你完成所有步骤:
在你的收件箱中搜索收据……
从你的电子邮件中找到订单号……
填写退货表格……
甚至安排 UPS 取件。
那是不是容易多了?
让我们再举一个更复杂一些的例子。
假设你刚搬到芝加哥。想象一下 Gemini 和 Chrome 能够共同协作帮助你做很多准备工作——代替你组织、推理、综合分析等。
比如,你想要探索这座城市并找到附近的服务——从干洗店到遛狗服务,你还必须在数十个网站上更新你的新地址。
现在 Gemini 可以胜任这些工作,并在需要时提示你提供更多信息。这样事情始终在你的掌控之中。
这部分非常重要——当我们做这些体验的原型设计时,我们深思熟虑如何以一种私密、安全且对每个人都适用的方式来进行。
这些都是简单的应用案例,但它们可以让你很好地了解到,通过构建能够代表你去提前思考、推理和计划的智能系统,我们希望能够解决的问题类型。
这对我们的使命意味着什么
Gemini 凭借其多模态、长上下文和智能体,使我们更接近我们的最终目标:让 AI 助力每个人。
我们认为,这是我们在达成使命方面取得最大进展的方式:整合以各种方式输入的全球信息,使其可以通过任何输出方式被获取,并将全球信息与你的世界中的信息结合起来,以一种真正对你有用的方式进行呈现。
新的突破
为了充分发挥 AI 的潜力,我们需要开创新领域,谷歌 DeepMind 团队一直致力于此。
我们已经收到了大家对 1.5 Pro 及其长上下文窗口的热情反馈,但我们也从开发人员那里了解到,他们想要更快、更具成本效益。因此,明天,我们将推出 Gemini 1.5 Flash,一个为规模化构建的更轻量级的模型,它针对以低延迟和成本为重的任务进行了优化。1.5 Flash 将于周二在 AI Studio 和 Vertex AI 中提供。
展望未来,我们始终希望构建一个在日常生活中有用的通用智能体。Astra 项目展示了多模态理解和实时对话能力。
我们还在视频和图像生成方面取得了进展,推出了 Veo 和 Imagen 3,并推出了 Gemma 2.0——我们为负责任的 AI 创新打造的下一代开放模型。
AI 时代的基础设施:介绍 Trillium
训练最先进的模型需要大量的计算能力。过去六年中,行业对机器学习计算能力的需求增长了 100 万倍。而且,每年都会以十倍的速度增长。
Google 在这方面具有优势。25 年来,我们一直在投资世界一流的技术基础设施,从支持搜索的尖端硬件,到为我们的 AI 进步提供支持的定制张量处理单元(tensor processing units)。
Gemini 完全在我们的第四代和第五代 TPU 上进行训练和服务。包括 Anthropic 在内的其他领先的 AI 公司也已经在 TPU 上训练了他们的模型。
今天,我们很高兴地宣布推出第六代 TPU—— Trillium。Trillium 是我们迄今为止性能最强、效率最高的 TPU,与上一代 TPU v5e 相比,每个芯片的计算性能提高了 4.7 倍。
我们将在 2024 年底向 Cloud 客户提供 Trillium。
除了我们的 TPU,我们还推出 CPU 和 GPU 来支持任何工作负载。这包括我们上个月宣布的新型 Axion 处理器,我们的首款基于 Arm 定制的 CPU,可提供业界领先的性能和能效。
我们也很自豪成为首批提供Nvidia(913.56,9.57,1.06%)尖端 Blackwell GPU 的 Cloud 提供商之一,该 GPU 将于 2025 年初上市。我们很幸运能与 NVIDIA 建立长期合作伙伴关系,并很高兴能将 Blackwell 的突破性功能带给我们的客户。
芯片是我们集成端到端系统的基础部分,从性能优化的硬件和开放软件到灵活的消费模式。所有这些都汇集在我们的 AI 超级计算机( AI Hypercomputer)中,这是一种开创性的超级计算机架构。
企业和开发者正在使用它来应对更复杂的挑战,其效率是仅购买原始硬件和芯片的两倍多。我们的 AI 超级计算机的进步之所以成为可能,是因为我们在数据中心采用了液体冷却的方法。
我们已经这样做近10年了,远早于它成为行业的先进技术。如今,我们部署的液体冷却系统总容量已接近 1 吉瓦,并且还在不断增长——这几乎是任何其他团队的 70 倍。
这背后的基础是我们庞大的网络规模,它连接了我们全球的基础设施。我们的网络覆盖了超过 200 万英里的陆地和海底光纤:是紧随之后的云服务提供商的 10 倍(!)以上。
我们将继续进行必要的投资,以推进 AI 创新并提供最先进的功能。

搜索最激动人心的篇章
我们最大的投资和创新领域之一是我们的创始产品——搜索。25 年前,我们创建了搜索,以帮助人们理解互联网上汹涌的信息浪潮。
随着每一次平台的转变,我们都在帮助更好地回答你的问题上取得了突破。在移动设备上,我们利用更好的上下文、位置感知和实时信息,解锁了新型的问题和答案。随着自然语言理解和计算机视觉技术的进步,我们实现了新的搜索方式,可以用语音或哼唱来找到你最喜欢的新歌;或者用你在散步时看到的那朵花的图像来进行搜索。现在,你甚至可以使用 Circle to Search 来搜索你可能想要购买的那些很酷的新鞋。去试试吧,反正你总能退货!
当然,Gemini 时代的搜索将把这一切提升到一个全新的水平,它将把我们的基础设施优势、最新的 AI 功能、对信息质量的高标准以及数十年来把你与丰富的网络连接起来的经验相结合。其结果将是一款为你工作的产品。
Google 搜索是生成式 AI,其规模足以满足人类好奇心。这是我们迄今为止最激动人心的搜索篇章。
更智能的 Gemini 体验
Gemini 不仅仅是一个聊天机器人;它旨在成为你得力的私人助手,可以帮助你处理复杂的任务并代表你采取行动。
与 Gemini 的互动应该是对话式的、直观的。因此,我们宣布推出称为 Live 的全新 Gemini 体验,让你可以使用语音与 Gemini 进行深入对话。我们还会在今年晚些时候将 Gemini Advanced 提升为 200 万个令牌,以便能够上传和分析视频和长代码等超密集文件。
Android 上 的 Gemini
全球有数十亿 Android 用户,因此我们很高兴能将 Gemini 更深入地融入用户体验。作为你的全新 AI 助手,Gemini 可随时随地为你提供帮助。我们已将 Gemini 模型整合到 Android 中,包括我们最新的设备端模型:Gemini Nano 多模态模型 (Gemini Nano with Multimodality),它可以处理文本、图像、音频和语音,在保证存储在设备上的信息私密性的同时解锁新的体验。
我们负责任的 AI 方法
我们继续大胆而振奋地把握住 AI 所带来的机遇。同时,我们也在确保以负责任的方法行事。我们正在开发一种叫做 AI 辅助红队测试 (AI-assisted red teaming) 的尖端技术,该技术利用了 Google DeepMind 在 AlphaGo 等游戏方面的突破以改进我们的模型。此外,我们也已将 SynthID 水印工具扩展到文本和视频两种新的模态,因此更容易识别 AI 生成的内容。
共同创造未来
所有这些都表明了我们在以大胆而负责任的方法,让 AI 助力每个人方面取得的重要进展。
很长一段时间以来,我们一直采用 AI 为先的方法。我们数十年的研究领导者地位开创了许多现代突破,为我们和整个行业的 AI 进步提供了动力。最重要的是,我们拥有:
专为 AI 时代打造的世界领先基础设施
现在由 Gemini 提供支持的搜索领域的尖端创新
在极大规模上提供帮助的产品——包括 15 款拥有 5 亿用户的产品
让每个人——合作伙伴、客户、创作者以及所有人——都能创造未来的平台。
这一进步之所以能够实现,是因为我们卓越的开发者社区。通过每天创建的体验和应用程序,你们将这一切变为现实。在此,我要向在 Shoreline 现场的各位以及全球数百万在线观看的朋友们致意:让我们共同迎接未来的无限可能,携手共创美好未来。
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管92.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.26
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管79.20
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照82.07
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管60.90
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56