马库斯锐评GPT-5:急需新范式OpenAI并无优势



有关GPT-5的消息最近又火起来了。
从最一开始的爆料,说OpenAI正在秘密训练GPT-5,到后来Sam Altman澄清;再到后来说需要多少张H100 GPU来训练GPT-5,DeepMind的CEO Suleyman采访「实锤」OpenAI正在秘密训练GPT-5。
然后又是新一轮的猜测。
中间还穿插了Altman的大胆预测,什么GPT-10会在2030年前出现,超过全人类的智慧总和,是真正的AGI云云。
再到最近OpenAI名叫Gobi的多模态模型,强势叫板谷歌的Gimini模型,两家巨头的竞争一触即发。
一时间,有关大语言模型的最新进展成了圈内最热门的话题。
套用一句古诗词,「犹抱琵琶半遮面」来形容,还挺贴切的。就是不知道,什么时候能真的「千呼万唤始出来」。
时间线回顾
今天要聊的内容和GPT-5直接相关,是咱们的老朋友Gary Marcus的一篇分析。
核心观点就一句话:GPT-4到5,不是光扩大模型规模那么简单,是整个AI范式的变化。而从这一点来看,开发出GPT-4的OpenAI并不一定是先到达5的那一家公司。
换句话说,当范式需要变革的时候,之前的积累可迁移性不大。
不过在走进Marcus的观点之前,我们还是简要复习一下最近有关传说中的GPT-5都发生什么了,舆论场都说了些什么。
一开始是OpenAI的联合创始人Karpathy发推表示,H100是巨头们追捧的热门,大家都关心这东西谁有,有多少。

然后就是一大波讨论,各家公司需要多少张H100 GPU来训练。

大概就是这样。
GPT-4可能在大约10000-25000张A100上进行了训练
Meta大约21000 A100
Tesla大约7000 A100
Stability AI大约5000 A100
Falcon-40B在384个A100上进行了训练
有关这个,马斯克也参与了讨论,根据马斯克的说法,GPT-5的训练可能需要30000到50000个H100。
此前,摩根士丹利也说过类似的预测,不过总体数量要比马斯克说的少一点,大概是25000个GPU。
当然这波把GPT-5放到台面上去聊,肯定少不了Sam Altman出来辟谣,表明OpenAI没在训练GPT-5.
有大胆的网友猜测,OpenAI之所以否认,很有可能只是把下一代模型的名字给改了,并不叫GPT-5而已。

反正根据Sam Altman的说法,正是因为GPU的数量不足,才让很多计划被耽搁了。甚至还表示,不希望太多人使用GPT-4。
整个业内对GPU的渴求都是如此。据统计,所有科技巨头所需的GPU加起来,得有个43万张还要多。这可是一笔天文数字的money,得差不多150亿美元。
但通过GPU的用量来倒推GPT-5有点太迂回了,于是DeepMind的创始人Suleyman直接在采访中「锤」了,表示OpenAI就是在秘密训练GPT-5,别藏了。
当然在完整的访谈中,Suleyman还聊了不少业内大八卦,比方说在和OpenAI的竞争中,DeepMind为啥就落后了,明明时间上也没滞后太多。
还有不少内部消息,比如当时谷歌收购的时候发生了什么。但这些跟GPT-5怎么着关系就不大了,有兴趣的朋友可以去自行了解。
总而言之,这波是业内大佬下场聊GPT-5的最新进展,让大伙不禁疑云陡起。
在这之后,Sam Altman在一场一对一连线中又表示,「我觉得2030年之前,AGI要出现,叫GPT-10,超过全人类的智慧总和。」

一方面大胆预测,一方面否认在训练GPT-5,这让别人很难真正知道OpenAI在做些什么。
在这场连线中,Altman设想了很多属于未来的图景。比如他自己怎么理解AGI,什么时候会出现AGI,真出现AGI了OpenAI会怎么办,全人类又该怎么办。
不过就实际进展来说,Altman是这么规划的,「我和公司中的员工说,我们的目标就是每12个月能让我们的原型产品性能提升10%。」
「如果把这个目标设定到20%可能就会有些过高了。」
这算是个具体安排。但是10%、20%和GPT-5之间的联系又在哪,也没说得很清楚。
最有含金量的还是下面这个——OpenAI的Gobi多模态模型。
重点在于谷歌和OpenAI之间的白热化竞争,到了哪个阶段。
说Gobi之前,先得说说GPT-vision。这一代模型就很厉害了。拍个草图照片,直接发给GPT,网站分分钟给你做出来。
写代码那更不用说了。
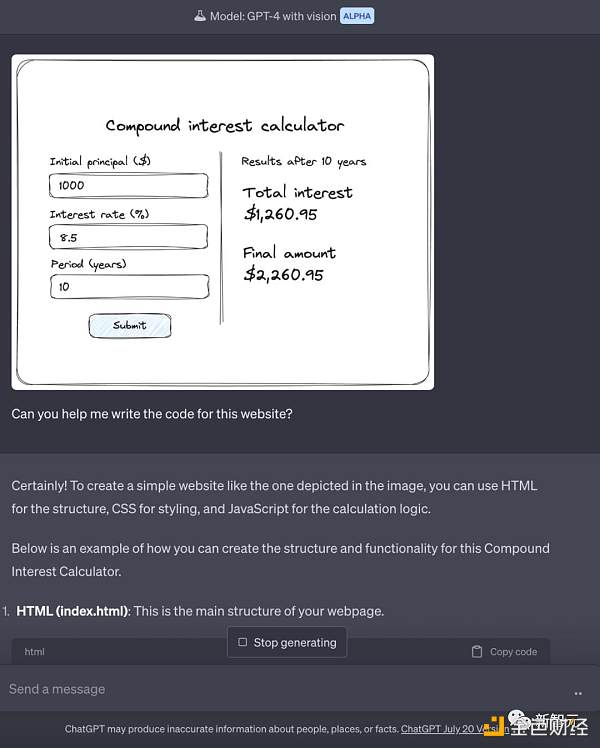
而GPT-vision完了,OpenAI才有可能会推出更强大的多模态大模型,代号为Gobi。
跟GPT-4不同,Gobi从一开始就是按多模态模型构建的。
这也让围观群众的兴趣一下被勾起来了——Gobi就是传说中的GPT-5吗?

当然现在我们还不知道Gobi训练到哪一步了,也没有确切消息。
而Suleyman还是坚定地认为,Sam Altman最近说过他们没有训练GPT-5,可能没有说实话。
Marcus观点
开宗明义,Marcus首先表示,很有可能,在科技史上,没有任何一款预发布的产品(iPhone可能是个例外)比 GPT-5被寄予了更多的期望。
这不仅仅是因为消费者对它的热捧,也不仅仅是因为一大批企业正计划着围绕它白手起家,甚至就连有些外交政策也是围绕GPT-5制定的。
此外,GPT-5的问世也可能加剧刚刚进一步升级的芯片战争。
Marcus表示,还有人专门针对 GPT-5 的预期规模模型,要求其暂停生产。
当然也是有不少人非常乐观的,有一些人想象,GPT-5可能会消除,或者至少是极大地消除人们对现有模型的许多担忧,比如它们的不可靠、它们的偏见倾向以及它们倾诉权威性废话的倾向。
但Marcus认为,自己从来都不清楚,仅仅建立一个更大的模型是否就能真正解决这些问题。
今天,有国外媒体爆料称,OpenAI的另一个项目Arrakis,旨在制造更小、更高效的模型,但由于没有达到预期目标而被高层取消。
Marcus表示,我们几乎所有人都认为,GPT-4之后会尽快推出GPT-5,而通常想象中的GPT-5要比GPT-4强大得多,所以Sam当初否认的时候让大伙大吃一惊。
人们对此有很多猜测,比方说上面提到的GPU的问题,OpenAI手上可能没有足够的现金来训练这些模型(这些模型的训练成本是出了名的高)。
但话又说回来了,OpenAI的资金充裕程度几乎不亚于任何一家初创公司。对于一家刚刚融资100亿美元的公司来说,即使进行5亿美元的训练也不是不可能。
另一种说法是,OpenAI 意识到,无论是训练模型还是运行模型,成本都将非常高昂,而且他们不确定能否在这些成本下盈利。
这么说好像有点道理。
第三种说法,也是Marcus的看法是,在Altman上半年5月份演讲的时候,OpenAI就已经进行过一些概念验证方面的测试了,但他们对得到的结果并不满意。
最后他们的结论可能是这样:如果GPT-5只是GPT-4的放大版而已的话,那么它将无法满足预期,和预设的目标差的还远。
如果结果只会令人失望甚至像个笑话一样,那么训练GPT-5就不值得花费数亿美元。
事实上,LeCun也是这么个思路。
GPT从4到5,不仅仅是4plus那么简单。4到5应该是划时代的那种。
这里需要的就是全新的范式,而不是单纯扩大模型的规模。
所以说,就范式上的变革来讲,当然还是越有钱的公司越有可能实现这个目标。但区别在于,不一定是OpenAI了。因为范式的变革是全新的赛道,过往的经验或者积累并不一定能派上多少用场。
同样,从经济的角度来讲,如果真如Marcus所言,那么GPT-5的开发就相当于被无限期的推迟了。谁也不知道新技术何时到来。
就好像,现在新能源汽车普遍续航几百公里,想要续航上千,就需要全新的电池技术。而新技术由谁来突破,往往除了经验、资金外,可能还需要那么一点点运气,和机缘。
但不管怎么说,如果Marcus想的是对的,那么未来有关GPT-5的各种商业价值想必会缩水不少。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管88.77
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47