东大华人博士让GPT-4用“心智理论”玩德扑 完胜传统算法 碾压人类新手



作者:新智元,来源:元宇宙之心
来自东京大学的Suspicion Agent利用GPT-4,在不完全信息博弈中表现出了高阶的心智理论能力(ToM)。
在完全信息博弈中,每个博弈者都知道所有信息要素。
但不完全信息博弈不同,它模拟了现实世界中在不确定或不完全信息下进行决策的复杂性。
GPT-4作为目前最强大模型,具有非凡的知识检索和推理能力。
但GPT-4能否利用已学习到的知识进行不完全信息博弈?
为此,东京大学的研究人员引入了Suspicion Agent这一创新智能体,通过利用GPT-4的能力来执行不完全信息博弈。

论文地址:https://arxiv.org/abs/2309.17277
在研究中,基于GPT-4的Suspicion Agent能够通过适当的提示工程来实现不同的功能,并在一系列不完全信息牌局中表现出了卓越的适应性。
最重要的是,博弈过程中,GPT-4表现出了强大的高阶心智理论(ToM)能力。
GPT-4可以利用自己对人类认知的理解来预测对手的思维过程、易感性和行动。
这意味着GPT-4具备像人类一样理解他人并有意影响他人的行为。
同样的,基于GPT-4的智能体在不完全信息博弈中的表现也优于传统算法,这可能会激发LLM在不完全信息博弈中的更多应用。
01 训练方法
为了让LLM能够在没有专门训练的情况下玩各种不完全信息博弈游戏,研究人员将整个任务分解为下图所示的几个模块,如观察解释器、游戏模式分析和规划模块。
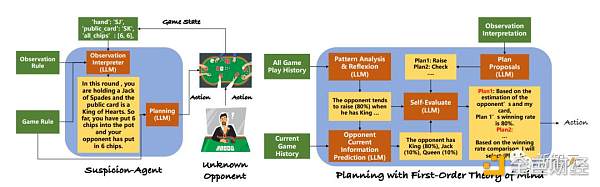
并且,为了缓解LLM在不完全信息游戏中可能会被误导这一问题,研究人员首先开发了结构化提示,帮助LLM理解游戏规则和当前状态。
对于每种类型的不完全信息博弈,都可以编写如下结构化规则描述:
一般规则:游戏简介、回合数和投注规则;
动作描述:(动作 1 的描述)、(动作 2 的描述)......;
单局输赢规则:单局输赢或平局的条件;
输赢回报规则:单局输赢的奖励或惩罚;
整局输赢规则:对局数和整体输赢条件。
在大多数不完全信息博弈环境中,博弈状态通常表示为低级数值,如单击向量,以方便机器学习。
但通过LLM,就可以将低层次的博弈状态转换为自然语言文本,从而帮助模式的理解:
输入说明:接收到的输入类型,如字典、列表或其他格式,并描述游戏状态中的元素数量以及每个元素的名称;
元素描述:(元素 11 的描述,(元素 2 的描述),....
转换提示:将低级游戏状态转换为文本的更多指南。
利用博弈规则和观测转换规则,可以有效地将低级博弈状态转换为可读文本,记为
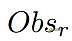
。
这种可读文本能够作为LLM的输入。使用
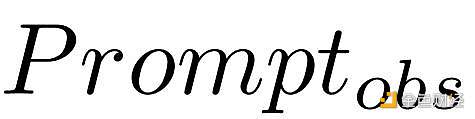
,生成文本中每个元素
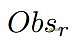
的条件分布可以建模为:
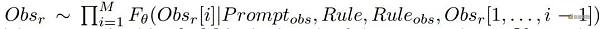
这里,
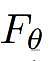
代表语言模型,参数为
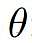
,M是生成文本
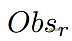
的长度,此模块命名为观察解释器。
在不完全信息博弈中,这种表述方式能更容易理解与模型之间的交互。
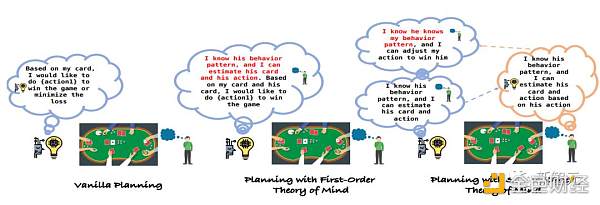
研究人员引入了一种虚无规划方法,该方法具有一个Reflexion模块,旨在自动检查对局历史,使LLMs能够从历史经验中学习和改进规划,以及一个单独的规划模块,专门用于做出相应的决策。
然而,虚无的规划方法往往难以应对不完全信息博弈中固有的不确定性,尤其是在面对善于利用他人策略的对手时。
受这种适应性的启发,研究人员设计出了一种新的规划方法,即利用LLM的ToM能力来了解对手的行为,从而相应地调整策略。
02 实验定量评估
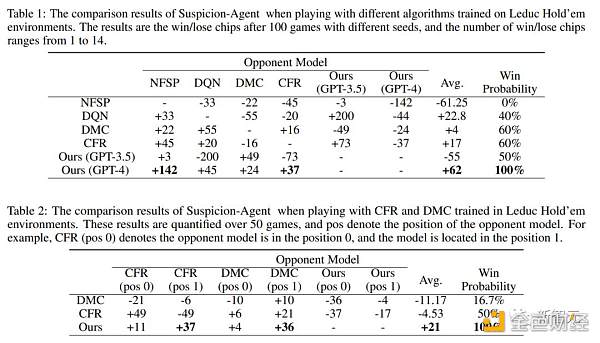
如表1所示,Suspicion Agent优于所有基线,并且基于GPT-4的Suspicion Agent在比较中获得了最高的平均筹码数。
这些发现有力地展示了在不完全信息博弈领域采用大型语言模型的优势,同时也证明了研究提出框架的有效性。
下图表明了Suspicion Agent和基线模型的行动百分比。
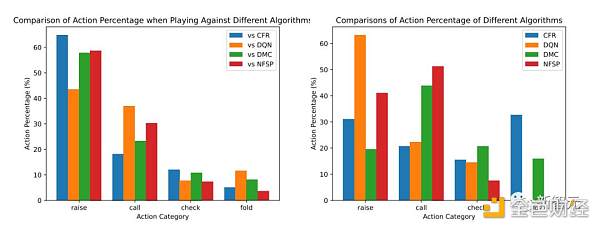
可以观察到:
Suspicion Agent vs CFR:CFR算法是一种保守策略,它倾向于保守,经常在持有弱牌时弃牌。
而Suspicion Agent成功识别了这一模式,并策略性地选择更频繁地加注,向 CFR 施加弃牌压力。
这使得即使Suspicion Agent的牌很弱或与CFR的牌相当的情况下,它积累了更多筹码。
Suspicion Agent vs DMC:DMC基于搜索算法,采用了更多样化的策略,包括虚张声势。它经常在自己手牌最弱和最强时都会加注。
作为回应,Suspicion Agent根据自己的手牌和观察到的DMC的行为,减少了加注频率,并更多地选择跟注或弃牌。
Suspicion Agent vs DON:DON算法的立场更加激进,几乎总是用强牌或中级牌加注,从不弃牌。
Suspicion Agent发现了这一点,并反过来尽量减少自己的加注,更多地根据公共牌和DON的行动选择跟注或弃牌。
Suspicion Agent Vs NFSP:NFSP表现出跟注策略,选择总是跟注并从不弃牌。
Suspicion Agent的应对方式是减少加注频率,并根据公共牌和NFSP观察到的行动选择弃牌。
根据上述分析结果,可以看到Suspicion Agent具有很强的适应性,能够利用其他各种算法所采用策略的弱点。
这充分说明了大语言模型在不完美信息博弈中的推理和适应能力。
03 定性评估
在定性评估中,研究人员在三个不完全信息博弈游戏(Coup、Texas Hold'emLimit 和 Leduc Hold'em)中对Suspicion Agent进行了评估。
Coup,中文翻译是政变,这是一种纸牌游戏,玩家扮演政治家,试图推翻其他玩家的政权。游戏的目标是在游戏中存活并积累权力。
Texas Hold'em Limit,即德州扑克(有限注),是一种非常流行的扑克牌游戏,有多个变体。「Limit」表示在每轮下注中有固定的上限,这意味着玩家只能下固定数额的赌注。
Leduc Hold'em是则是德州扑克的一个简化版本,用于研究博弈论和人工智能。
在每种情况下,Suspicion Agent手中有一张Jack,而对手要么有一张Jack,要么有一张Queen。
对手最初选择跟注而不是加注,暗示他们手牌较弱。在普通计划策略下,Suspicion Agent选择跟注以查看公共牌。
当这揭示出对手手牌较弱时,对手迅速加注,使Suspicion Agent处于不稳定的局面,因为Jack是最弱的手牌。

在一阶理论心智策略下,Suspicion Agent选择弃牌,以最小化损失。这个决定是基于观察到对手通常在手中有Queen或Jack时才跟注。

然而,这些策略未能充分利用对手手牌的推测弱点。这一缺点源于它们不考虑Suspicion Agent的举动可能如何影响对手的反应。

相比之下,如图9所示,简单的提示能够让Suspicion Agent了解如何影响对手的行动。有意选择加注会给对手带来压力,促使他们弃牌并最小化损失。
因此,即使手牌的强度相似,Suspicion Agent也能够赢得许多比赛,从而比基线赢得更多的筹码。

此外,如图10所示,在对手跟注或回应Suspicion Agent的加注情况下(这表明对手手牌强大),Suspicion Agent就会迅速调整策略,选择弃牌以防止进一步损失。

这显示了Suspicion Agent的出色战略灵活性。
04 消融研究与组件分析
为了探索不同阶ToM感知规划方法如何影响大型语言模型的行为,研究人员在Leduc Hold'em和plaagainst CFR上进行了实验和比较。
图5中展示了采用不同ToM水平规划的Suspicion Agent的行动百分比,并在表3中展示了筹码收益结果。
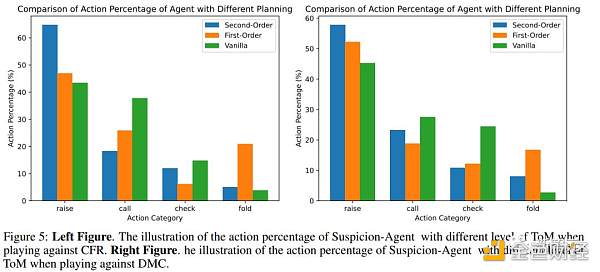
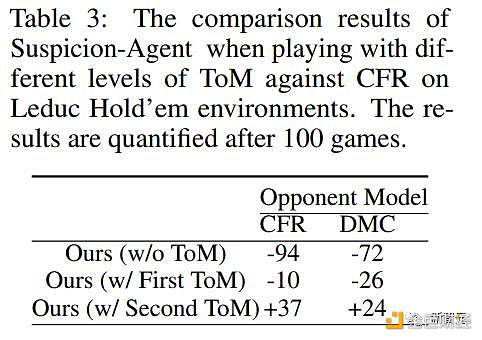
表3:Suspicion Agent在使用不同级别ToM与CFRonLeduc Hold'em环境对弈时的比较结果以及100局游戏后的量化结果
可以观察到:
基于Reflexion modulevanilla规划在对局过程中倾向于更多地跟注和过牌(在对阵CFR和DMC时跟注和过牌比例最高),这无法施加压力使对手弃牌,并导致许多不必要的损失。
但如表3所示,vanilla计划的筹码收益最低。
利用一阶ToM,Suspicion Agent能够根据自己的牌力和对对手牌力的估计做出决策。
因此,它加注的次数会多于普通计划,但它弃牌的次数往往多于其他策略,目的是尽量减少不必要的损失。然而,这种谨慎的方法会被精明的对手模型所利用。
例如,DMC经常在拿着最弱的一手牌时加注,而CFR有时甚至会在拿着中级牌时加注,以对Suspicion Agent施加压力。在这些情况下,Suspicion Agent的加倍倾向会导致损失。
相比之下,Suspicion Agent更擅长识别和利用对手模型的行为模式。
具体来说,当CFR选择过牌(通常表示手牌较弱)或当DMC过牌(表明其手牌与公共牌不一致)时,Suspicion Agent会以虚张声势的方式加注,诱使对手弃牌。
因此,Suspicion Agent在三种规划方法中表现出最高的加注率。
这种激进的策略让Suspicion Agent即使手持弱牌也能积累更多筹码,从而最大限度地提高筹码收益。
为了评估后视观察的影响,研究人员进行了一项后视观察不纳入当前游戏的消融研究。
如表4和表5所示,在没有后视观察观察的情况下,Suspicion Agent仍能保持其相对于基线方法的性能优势。
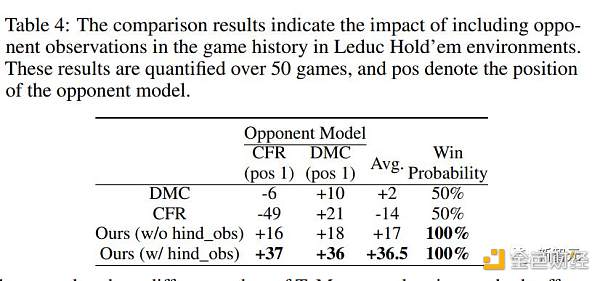
表4:比较结果表明了在莱德克牌局环境中将对手观察结果纳入对局历史的影响

表5:比较结果表明,当Suspicion Agent在 Leduc Hold'em 环境中与CFR对弈时,在对局历史中加入对手观察结果的影响。结果是使用不同种子进行100局对局后的输赢筹码,输赢筹码数从1到14不等
05 结论
Suspicion Agent没有进行任何专门的训练,仅仅利用GPT-4的先验知识和推理能力,就能在Leduc Hold'em等不同的不完全信息游戏中战胜专门针对这些游戏训练的算法,如CFR和NFSP。
这表明大模型具有在不完全信息游戏中取得强大表现的潜力。
通过整合一阶和二阶理论心智模型,Suspicion Agent可以预测对手的行为,并相应调整自己的策略。这使得它可以对不同类型对手进行适应。
Suspicion Agent还展示了跨不同不完全信息游戏的泛化能力,仅仅根据游戏规则和观察规则,就可以在Coup和Texas Hold'em等游戏中进行决策。
但Suspicion Agent也有着一定的局限性。例如,由于计算成本限制,对不同算法的评估样本量较小。
以及推理成本高昂,每局游戏耗费接近1美元,并且Suspicion Agent的输出对提示的敏感性较高,存在hallucination的问题。
同时,在进行复杂推理和计算时,Suspicion Agent的表现也不尽人意。
未来,Suspicion Agent将在计算效率、推理鲁棒性等方面进行改进,并支持多模态和多步推理,来实现对复杂游戏环境的更好适应。
同时,Suspicion Agent在不完全信息博弈游戏中的应用,也可以迁移到未来多模态信息的整合,模拟更真实的交互、扩展到多玩家游戏环境中。
参考资料:
https://arxiv.org/abs/2309.17277
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管88.77
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47