颠覆AI领域格局 Meta发布Llama 2:开源、免费、可商用



在上周推出的Threads对抗Twitter以创纪录的速度突破1亿用户后,周二,Meta再次与微软强强联手,针对大语言模型领域向谷歌和OpenAI发起了新的挑战。这一系列动作使得Meta在人工智能领域引起了广泛关注,展现出了其强大的实力和野心。
随着人工智能技术的迅猛发展,各大科技公司争相发布先进的模型,希望在这个竞争激烈的领域中脱颖而出。在这个背景下,Meta 在周二发布了最新一代开源大模型Llama 2,为人工智能领域带来了新的突破。Llama 2相较于今年2月发布的Llama 1,进行了许多重要的改进,彰显了Meta在人工智能领域的实力和创新精神。

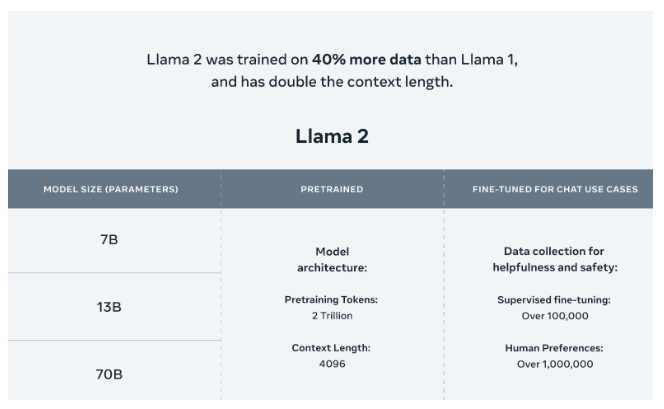
据Meta官网透露,Llama 2的最显著改进之一是训练所用的token数量翻了一倍,这意味着模型在训练过程中能够处理更多的文本信息,提升了其语言理解和生成能力。
同时,Llama 2还对于使用大模型最重要的上下文长度限制进行了提升,将限制的长度翻倍。这使得Llama 2能够更好地捕捉上下文信息,提供更准确的回答和生成结果。这些改进为Llama 2赋予了更强大的智能能力,使其能够更好地适应不同应用场景和任务的需求。
Llama 2包含了三个不同规模的模型,分别是70亿、130亿和700亿参数的版本。
这种多样性使得用户可以根据自己的需求选择适合的模型规模,平衡模型性能和计算资源之间的关系。
无论是需要更快速的推理速度还是更高精度的结果,用户都能够找到适合自己的解决方案。

与此同时,Meta还宣布与微软云服务Azure合作,将基于Llama 2模型的云服务首发给全球开发者。这意味着开发者可以利用Meta的大型语言模型进行开发和构建商业产品,并且可以借助Azure的强大云原生工具进行内容过滤和安全功能的支持。这种合作关系将为开发者提供更便捷和完善的工作流程,推动人工智能技术在各行各业的应用和创新。
除了与Azure的合作,Meta还与高通达成了合作协议,使得Llama 2能够在高通芯片上运行。这一合作打破了市场上英伟达和AMD处理器对AI产业的垄断,为AI技术的普及和发展带来了更多可能性。通过在高通芯片上的运行,Llama 2可以在移动设备等端侧环境中发挥其强大的能力,提供更高效、低延迟的人工智能应用体验。
结语
Meta在AI用户争夺战上的落后情况促使其改变策略,不再像OpenAI和谷歌那样专注于非开源语言模型路线。相反,开放生态成为Meta目前的一个重要切入点。
通过开源,Meta将获得更多的可训练数据,并且能够借助开发人员的帮助来发现和解决Llama 2中的漏洞,从而不断提升模型的质量。
此外,开源还能够帮助Meta更快地渗透市场,为将来的商业化奠定基础。从某种程度上说,Meta此举也是在向OpenAI和谷歌施加压力,展示其在人工智能领域的实力和竞争力。
Meta一直致力于开发开源人工智能,而Llama 2的发布标志着他们在这一领域的重要进展。与去年发布的ChatGPT相比,Meta通过Llama 2进一步扩展了其模型家族,为用户提供更多选择和灵活性。
Llama 2是Meta推出的第一个免费使用的大型语言模型,用户可以从Microsoft Azure、Amazon Web Services和Hugging Face等渠道下载和使用。与OpenAI的ChatGPT不同,Llama 2的使用需要从Meta的合作伙伴处获取。
通过发布Llama 2,Meta希望能够迅速迎头赶上竞争对手,争夺在人工智能领域的霸主地位。
据悉,Meta已经准备好开源Llama 2的下一版本,并将其用于研究和商业用途。他们还提供了预训练模型和对话微调版本的模型权重和起始代码,使得开发者可以更好地利用Llama 2进行定制化的应用开发。
Meta 发布的Llama 2 实现了人工智能领域的再次重要突破。通过提升模型规模和能力,并与微软和高通等公司展开合作,Meta为用户和开发者提供了更强大、灵活和便捷的人工智能工具,推动了人工智能技术的创新和应用发展。
随着Llama 2的开源和免费使用,我们可以期待更多有趣和有用的人工智能应用将会涌现出来,开创人工智能的新时代。
声明:本文来自潮外音创作者,内容仅代表作者观点和立场,且不构成任何投资建议,请谨慎对待,如文章/素材有侵权,请联系官方客服处理。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管92.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.26
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管79.20
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照82.07
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管60.90
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56