零知识处理单元(ZPU)设计方案介绍—— 多功能及可编程的ZK硬件加速器



作者:Ingonyama,Medium;编译:Kate, Marsbit
TL;DR:
在本博客中,我们提出了零知识处理单元(ZPU),这是一种通用的可编程硬件加速器,旨在解决零知识处理的新需求。
我们将介绍ZPU架构和设计注意事项。我们解释了ZPU生态系统不同部分背后的设计选择:ISA,数据流,内存和处理元件(PE)内部结构。最后,我们将 ZK 和全同态加密 (FHE) 与最先进的 ASIC 架构进行比较。
介绍
数据驱动的应用程序的快速增长和对隐私的日益增长的需求导致了对保护敏感信息的加密协议的兴趣激增。在这些协议中,零知识证明(ZKP)作为确保计算完整性和隐私性的强大工具脱颖而出。ZKP使一方能够在不泄露任何额外信息的情况下向另一方证明声明的有效性。这一特性导致ZKP在各种以隐私为重点的应用中得到广泛采用,包括区块链技术、安全云计算解决方案和可验证的外包服务。
然而,在实际应用程序中采用ZKP面临着一个重大挑战:与证明生成相关的性能开销。ZKP算法通常涉及对非常大的整数的复杂数学运算,例如椭圆曲线上的大型多项式计算和多标量乘法。此外,密码算法在不断发展,新的和更有效的方案正在快速发展。因此,现有的硬件加速器很难跟上各种各样的加密原语和不断变化的加密算法。
在这篇博客中,我们提出了零知识处理单元(ZPU),这是一种新颖的多功能硬件加速器,旨在解决零知识处理的新需求。ZPU建立在指令集架构(ISA)上,支持可编程性,使其能够适应快速发展的加密算法。ZPU 具有处理元件 (PE) 的互连网络,具有对大字模块化算法的本地支持。PE的核心结构受到乘法累加(MAC)引擎的启发,该引擎是数字信号处理(DSP)和其他计算系统中的基本处理元素。PE的运算符使用模块化算法,其核心组件专门用于支持ZK算法中的常见运算,例如NTT蝴蝶运算和用于多标量乘法的椭圆曲线点加法。
指令集架构
ZPU架构的特点是一个由指令集架构(ISA)定义的处理元件(PE)的互连网络,如下图1所示。我们选择这种架构是为了适应零知识协议不断变化的环境。
ISA 方法使 ZPU 能够保持灵活性,适应ZK算法的变化,并支持广泛的加密原语。此外,使用ISA而不是固定的硬件可以在制造后持续改进软件,确保即使在该领域出现新的进展,ZPU也能保持相关性和效率。
ISA是处理器可以执行的一组指令。它作为硬件和软件之间的接口,定义了软件与硬件交互的方式。通过定制ISA来设计ZPU,我们可以针对ZK处理任务的特定要求对其进行优化,例如大字模算术运算、椭圆曲线加密和其他复杂的密码运算。
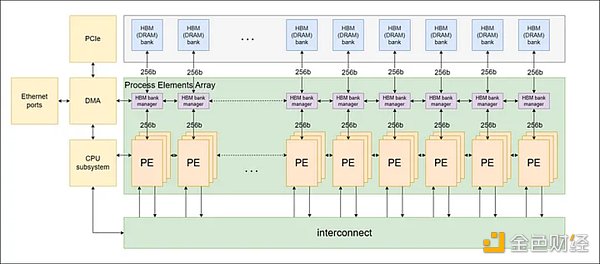
图1:PE网络结构
PE核心部件
每个PE都设计了一个内核,其中包括模乘法器、加法器和减法器,如图2所示。这些核心组件的灵感来自数字信号处理(DSP)和其他计算系统的基本处理元件,乘法累加(MAC)引擎。MAC引擎有效地执行乘法累加运算,包括将两个数字相乘并将乘积加到累加器中。
PE的核心结构是为ZK中常见的运算量身定制的,例如用于多标量乘法的椭圆曲线点加法和用于数论变换(NTT)的NTT蝴蝶运算。蝴蝶运算包括加法、减法和乘法,都是在模运算下进行的。该操作的名称来源于其计算流程图的蝴蝶外观,它非常适合PE的核心硬件组件,因为它们通过专用的蝴蝶指令实现原生蝴蝶计算。
此外,每个PE包含几个专用内存单元,包括:
1.到达休息室:用于存储到达PE的数据的存储器。
2.出发休息室:用于存储从PE出发的数据的存储器。
3.操作数A、B和C的暂存存储器:三个单独的存储器用于存储中间结果。
4.内存扩展器:用于处理各种算法需求的多用途内存,例如用于多标量乘法(MSM)的桶聚合。
5.程序存储器:用于存储指令队列的存储器。
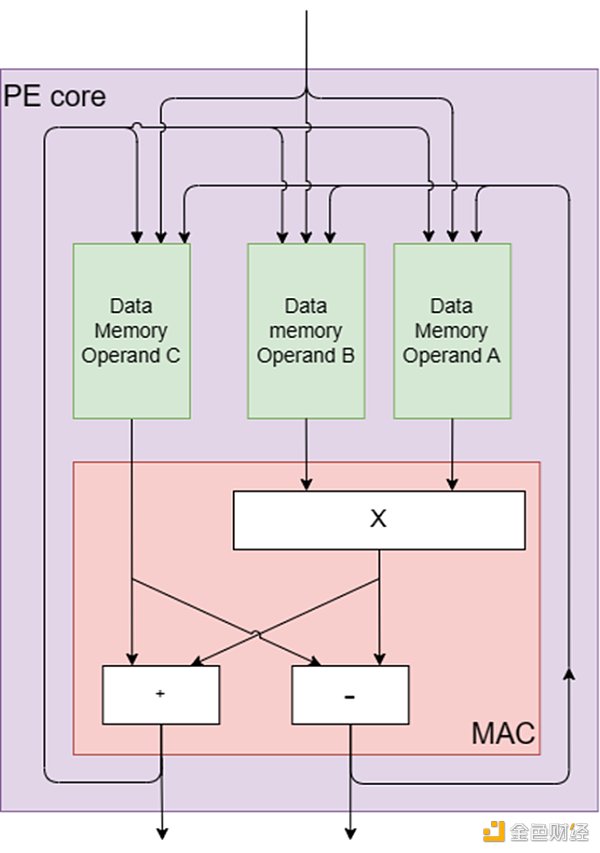
图2:PE核心组件
PE位宽
PE本机支持大字模块算术运算(最多256位字)。PE中高位宽本机支持和低位宽本机支持之间的权衡源于需要平衡不同操作数大小的效率。
当PE具有高位宽本机支持时,它会针对处理大操作数大小进行优化,而不需要将它们分解成更小的块。然而,这种优化的代价是较小位宽操作的效率降低,因为PE未得到充分利用。另一方面,当PE具有低位宽本机支持时,它被优化为更有效地处理小操作数大小。然而,当处理较大位宽的操作时,这种优化会导致效率低下,因为PE需要将较大的操作数分解成较小的块,并依次处理这些块。
挑战在于找到高低位宽本机支持之间的适当平衡,以确保在广泛的操作数大小范围内进行有效处理。这种平衡应该考虑目标应用程序领域(即ZK协议)中普遍存在的常见位宽度,并权衡每种设计选择的优缺点。在ZPU架构的情况下,选择256位字长作为一个很好的平衡。
PE的连接
所有PE之间采用环形连接,每个PE直接与相邻的两个PE相连,形成一个环形网络。这种环形连接允许控制数据在不同PE之间有效地传播。PE也通过互连组件连接,这是一种类似于桶形移位器的机制,可以随着时间的推移在不同的PE之间实现直接连接。这种设置允许PE发送和接收来自所有其他PE的信息。
周边组件
该架构还集成了片外高带宽内存(HBM),以支持高内存容量和高内存带宽。将多个PE聚在一起组成一个PE集群,每个PE集群与一个HBM bank或信道相连。此外,还包括一个基于ARM的片上CPU子系统来管理整个系统操作。
绩效评估
为了评估ZPU的性能,我们考虑了我们旨在加速的算法的关键操作。我们主要研究的是NTT蝴蝶运算和椭圆曲线(EC)点加法运算。为了评估MSM和NTT操作的总计算时间,我们计算了它们所需的计算指令的总量,并将它们除以时钟频率和PE的数量。
NTT 蝶形运算在每个时钟周期执行。对于多标量乘法(MSM)中的关键元素椭圆曲线点加法运算,我们将其解构为可以在单个PE上执行的基本机器级指令。我们随后计算完成此操作所需的时钟周期数。通过分析,我们确定每个椭圆曲线点相加运算可以每18个时钟周期执行一次。
这些假设为我们的性能评估提供了基础,并且可以根据需要进行调整,以反映不同的算法要求或硬件功能。
根据我们的计算,在GPU的1.305 GHz频率上运行72个PE的配置足以匹配Zprize的MSM操作中GPU类别获胜者的性能。Yrrid Software和Matter Labs都实现了这一壮举,使用A40 NVIDIA GPU每4次MSM计算达到2.52秒的结果。该比较基于固定基点 MSM 计算,涉及从 BLS 12-377 标量场中随机选择的 2²⁶ 标量,以及来自 BLS 12-377 G1 曲线的一组固定椭圆曲线点和有限的随机采样输入向量来自标量场的场元素。
根据我们对PE的面积估计,使用8nm工艺的ASIC,与A40 GPU中采用的工艺技术相同,可以在与A40 GPU相同的628 mm2面积内容纳大约925个PE。这意味着我们实现了比A40 GPU高约13倍的效率。
PipeZK是一种高效的流水线加速器,旨在提高零知识证明(ZKP)生成的性能,具有专用的MSM和NTT内核,分别优化了多标量乘法和大型多项式计算的处理。
与 PipeZK 相比,我们发现仅 17 个以 PipeZK 频率 300 MHz 运行的 PE 的配置就足以匹配 PipeZK 的 MSM 操作性能。PipeZK在BN128曲线中的2²⁰长度的MSM上以 300 MHz 执行 MSM 操作,耗时0.061秒完成。此外,为了匹配PipeZK的NTT操作性能,在300MHz下运行256位元素的2²⁰元素NTT,耗时0.011秒,我们需要大约 4 个以相同频率运行的 PE。总的来说,为了匹配PipeZK同时运行MSM和NTT的性能,我们需要21个PE。
根据我们的面积估计,使用28nm工艺的ASIC(与PipeZK中采用的工艺技术相同)可以在与PipeZK芯片相同的50.75 mm2面积内容纳大约16个PE。这意味着我们的效率略低于PipeZK的固定架构(效率低25%),同时仍然可以完全灵活地适应不同的椭圆曲线和ZK协议。
环处理单元(RPU)是最近的一项工作,旨在加速基于环的带错误学习(RLWE)的计算,这是各种安全和隐私增强技术的基础,如同态加密和后量子加密。
与RPU相比,我们的计算表明,当计算128位元素的64K NTT时,为了匹配RPU在最佳配置(128 bank和HPLEs)下的性能,我们将需要大约23个PE在RPU的1.68GHz频率上运行。我们的分析表明,采用与RPU相同的12nm工艺技术的ASIC可以在RPU占用的20.5 mm²面积内容纳大约19.65个PE。这意味着我们的效率略低于RPU(效率低15%),同时与NTT以外的原语兼容。
TREBUCHET是一个完全同态加密(FHE)加速器,它使用环处理单元(RPU)作为片上区块。切片还通过将数据调度到接近计算元素的位置来促进内存管理。RPU在整个设备中被复制,使软件能够最大限度地减少数据移动并利用数据级并行性。
TREBUCHET和ZPU都基于ISA架构和大型算术单词引擎,这些引擎在模块化算法下支持非常长的单词(128位或更高)。然而,与RPU或TREBUCHET SoC相比,ZPU的附加价值在于它扩大了该架构旨在解决的问题集。RPU和TREBUCHET主要关注NTT,而ZPU支持更多的原语,如多标量乘法(MSM)和面向算术的哈希函数。
总结
我们的性能评估表明,ZPU可以匹配甚至超过现有最先进的ASIC设计的性能,同时对ZK算法和加密原语的变化提供更大的适应性。虽然需要考虑权衡,例如PE 中高位宽和低位宽支持之间的平衡,但ZPU的设计经过精心优化,以确保在广泛的操作数尺寸范围内进行高效处理。对于那些有兴趣了解更多关于ZPU或探索潜在合作的人,请随时与我们联系。我们期待与大家分享更多关于ZPU项目进展和未来发展的最新信息。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管92.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.26
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管79.20
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照82.07
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管60.90
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56