腾讯领投的 AIGC 是什么 前有chatGPT 巨头闻风而来



OpenAI 的 AIGC(Generative AI)的火爆让更多的加密行业用户接触到这项技术。随着用户越来越熟悉它,他们能够认识到它的潜力。AIGC 降低了创意表达的门槛,使普通人能够通过制作符合专业标准的作品来展示他们的想象力和创造力。
我们的基础模型拥有超过 4000 亿个参数,允许用户生成范围广泛的内容,或训练他们自己的模型以涵盖任何主题或风格。

2023年开始,AIGC开启了人机共生时代。AIGC 不仅变得更快、更便宜,而且由于其更快、更广泛的学习,在某些情况下甚至比手动创建的更好。每一个需要原创创意的行业,从社交媒体到游戏,广告到行业咨询,编码到建筑和平面设计,产品设计到法律文件,市场营销到销售,都将被重塑,一些重复性的工作可能会被生成式AI完全取代. 随着人机共生继续渗透到许多行业,它们将在人与机器之间紧密的创造力迭代循环中蓬勃发展,在广泛的市场中解锁更好、更快和更便宜的创造。人机共生的愿景是辅助决策、数据分析、体力劳动等任务,将人类解放出来,专注于需要人类创造力和判断力的更高层次的任务和活动。生成式人工智能将使创造和决策的边际成本降至零,产生巨大的劳动生产率和经济价值——以及相应的市场价值。
AIGC是一种利用人工智能生成内容的技术。2015年成为行业转折点,在此之前AIGC主要是生成文本和语音。此后,AIGC不断拓展,涵盖了文字、语音、图像、视频、3D等新领域,在创意、行为、表现、理解、个性化等方面具有巨大优势。最早的 AIGC 模型是生成对抗网络(GAN)。
GAN的基本原理其实很简单。这里我以生成图片为例进行说明。假设我们有两个网络,G(生成器)和 D(鉴别器)。顾名思义,G 是一个生成图像的网络。它接收随机噪声 z 并通过该噪声生成图像,表示为 G(z)。D 是一个判别网络,用于确定图像是否“真实”。它的输入参数是x,表示一幅图像,输出D(x)表示x是真实图像的概率。如果为1,表示100%是真实图像,如果输出为0,表示不可能是真实图像。在训练过程中,生成器网络 G 的目标是生成尽可能真实的图像以欺骗鉴别器网络 D。另一方面,D 的目标是将 G 生成的图像与真实图像区分开来。这样,G和D就形成了一个动态的“博弈过程”。这场比赛的结果如何?在理想状态下,G 能够生成足够“具有欺骗性”的图像 G(z)。对于D,很难判断G生成的图像是否真实,所以D(G(z)) = 0.5。至此,我们的目标就达到了:我们得到了一个可以用来生成图像的生成模型G。

GAN 和传统的自然语言理解模型的缺点是它们在结构化创造力和联想方面的能力有限,这导致它们缺乏令人印象深刻的应用。
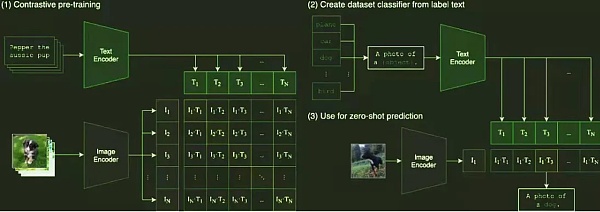
在2020年,OPENAI开发了跨模态预训练深度学习模型GPT(Generative Pre-Training Transformer)及其变体CLIP(Contrastive Language-Image Pre-Training)并开源。CLIP 模型能够通过首先收集 40 亿个未处理的图像+文本对的数据集和预训练来完成任务,从而将文本与图像相关联。它使用对比学习目标进行训练:分别对图像和文本(其中文本是一个完整的句子)进行编码,然后计算它们之间的余弦相似度,然后对图像的每一行或文本的每一列进行分类,找到匹配的正例例子。每张图片有 32,768 个文本候选,是 SimCLR 的两倍,反例数量的增加也是性能不错的原因之一。预测也很简单:找一个图像分类数据集,将标签转换为自然语言,比如“dog”可以转换为“a photo of a dog”。然后使用预训练的编码器对标签和图像进行编码,然后计算相似度。
整个过程可以概括为:输入一张图片,预测数据集中 32768 个随机抽取的文本片段中的哪一个与数据匹配。由于文本描述不是特定类别,零样本学习可以用于各种图像分类任务。零样本学习是一种迁移学习,例如,对斑马的描述可能是“马轮廓+虎皮毛+熊猫黑白”以生成新类别。一个典型的监督分类器可以正确分类马、老虎和熊猫的图像,但是如果它遇到一张它以前没有学过的斑马照片,它就无法分类。然而,由于斑马与已经分类的图像有共性,可以推断它属于这个新类别。
所以想法是设置更细粒度的类别作为属性,以便在测试集和训练集之间建立联系。例如,将马的特征向量转换为语义空间,其中每个维度代表一个类别的描述,比如[有尾巴1,马的轮廓1,有条纹0,黑白0],熊猫将是 [有尾巴 0,马的轮廓 0,有条纹 1,黑色和白色 1]。这样,通过为斑马定义一个向量并比较输入图像的向量与斑马向量之间的相似度,我们可以确定输入图像是否为斑马。
因此,CLIP模型有两个优点:
一方面,它同时进行自然语言理解和计算机视觉分析,实现图文匹配。
另一方面,为了有足够的标记良好的“文本图像”用于训练,CLIP模型广泛使用来自互联网的图片,这些图片通常具有各种文本描述,成为CLIP的天然训练样本。据统计,CLIP模型已经从互联网上收集了超过40亿条“文本-图像”训练数据,使CLIP能够进行图像和文本匹配,并作为各种自然语言处理和计算机视觉应用的基础,例如 AIGC 系统,它允许用户输入文本并生成图像或视频。
由于GPT和CLIP的开源,Denoising Diffusion模型迅速成熟并得到实施。真正让文字生成图像的AIGC,随着Dalle-2、Midjourney、Stable Diffusion等应用的推出,在2022年下半年为大众所熟知。
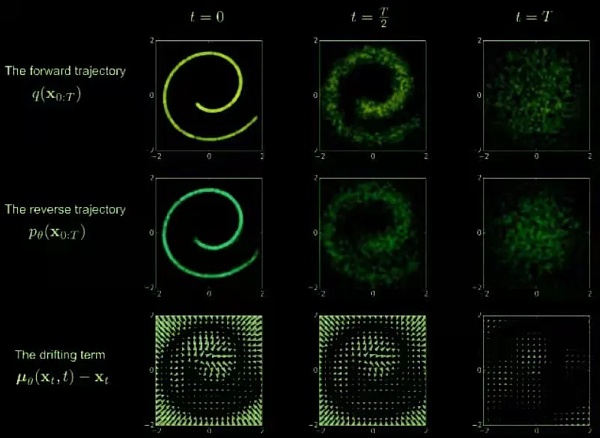
扩散模型的思想来自非平衡热力学。具有定义的扩散步骤(当前状态仅取决于先前状态)的马尔可夫链被真实数据中的随机噪声缓慢扰动(正向过程),然后学习反向扩散过程(逆向过程)以构造从噪声中提取所需的数据样本。
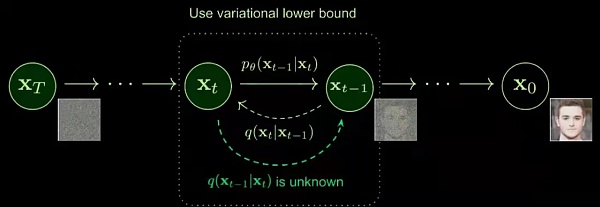
正向过程是一个连续注入噪声的过程,随着时间的推移,加入的噪声不断增加。根据马尔可夫定理,噪声注入后的当前时刻与前一时刻的相关性也与要加入的噪声有关(是前一时刻的影响更大还是加入的噪声影响更大)。随着前向过程在时间上向前推进,噪声或随机事件的影响可能会变得更加显着,因为开始时一点点噪声都有影响,后面需要加入越来越多的噪声。
逆过程从一个随机噪声开始,逐渐恢复出没有噪声的原始图像——去噪和实时数据生成。这里,我们需要知道整个数据集,所以我们需要学习一个神经网络模型(目前主流的是U-net+attention结构)来逼近这些条件概率,运行反向扩散过程。
未来
毫无疑问,未来是光明的
我们看到了AIGC充满活力的应用,也知道了方向。当你看到机器产生复杂的功能代码或优秀的图像时,你不得不承认,人机共生的时代终于到来了,机器在我们的工作和创作中起着基础性的辅助作用。
或许在不久的将来,我们就能写出心中想象的神话世界;打印出我们能想到的任何东西;在影院观看我们自己制作的电影;让全世界的玩家都沉浸在我们制作的电子游戏中,获得良好的游戏体验。在短短的几年时间里,AIGC 从一个小型的开源架构迅速训练到一个拥有数千亿参数的大型模型。如果我们继续以这种发展速度发展,并遵循大型模型的摩尔定律,这些未来主义场景可能会变得触手可及。
领投机构

创始团队

JP.crypto
Web3前沿动态社区,专注于项目投研与价值投资。加入我们获取更多项目信息。
推特:https://twitter.com/Crytpojp_JP
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管89.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47