行业解读 | 狂飙的ChatGPT 进军的预言机



前言:如果说,ChatGPT的出现,象征着一场新的、关于“智能”的工业革命的萌芽正破土而出。那么,预言机的落地,代表着一次新的,关于“数据”的区块链变革的哥伦布之旅。
“你是谁?”
“我是一个由OpenAI训练的大型语言模型。我旨在帮助人们解答问题和提供信息。由于我是一个计算机程序,所以不会感知或者思考,只能通过已有的数据来回答问题。如果您有任何问题,请随时告诉我。”
ChatGPT:挖掘数据价值
ChatGPT,无疑是近期互联网上最火的一个话题。据《财富》报道,ChatGPT在发布仅仅五天后就完成了Facebook耗时10个月才完成的目标——用户超过100万。2月1日,ChatGPT月活用户破1亿人,ins实现这一数据用时两年,TikTok用时9个月,而ChatGPT仅用60天。
火爆程度,可见一斑。
作为这个时代技术的杰出结晶,ChatGPT带来的是不可预知的革命。无论你喜欢不喜欢,以ChatGPT为代表的AIGC(生成式人工智能)将改变世界。
比尔盖茨也意味深长地说:ChatGPT出现的重大历史意义,不亚于PC和互联网诞生。

伴随着ChatGPT的诞生,其愈发强大的AIGC(生成式人工智能)能力使得不少职业人陷入“职场危机”。甚至有人会担心AI会不会取代人类。其实,AI代替人类工作的言论,并不是第一次出现,几年前便初见端倪。
2017年12月麦肯锡全球研究院(McKinsey Global Institute)发布的《失业与就业:自动化时代的劳动力转型》报告称,到2030年,保守估计全球15%的人将因AI技术发展而发生工作变动,激进预估则影响30%的全球人口,中国届时预计有几千万至上亿人需重新就业。
当人们仍对报告中的预测不以为意时,2022年9月,科罗拉多州博览会艺术比赛的数字类别中,AI画作《太空歌剧院》一举夺魁,再次引发“AI能否取代人类”的巨大争论。如今,ChatGPT的横空出世,引发全球规模的对AI“威胁”就业所产生的职业生存焦虑的讨论。
毫无疑问,ChatGPT是当前人工智能领域重大突破的杰作,同时,不可否认的是,ChatGPT依然存在很多问题。尽管ChatGPT一个基于统计规律的大语言模型,它有人类无懈可击的语言天赋,但是只能做联想而不能完成“逻辑推理”。从这个角度来讲,ChatGPT会倾向于制造出令人信服的回应,当然其中可能包含“生成的”几个事实错误、虚假陈述和错误数据,因为作为一个自然语言处理模型,它也不知道高达数十PB的无监督训练数据里什么是“事实”,这更像一个有点滑头的“虚拟助手”。
另外,因为在训练过程中,为了识别人类指令而注入过大量“指令”知识,ChatGPT会对“指令”本身非常敏感,但同时会对一些上下文无关,需要“事实依据”做判断的歧义词识别不高。也许,对大多数普通人来说,ChatGPT都是一个合格的助手,因为所有关于人类语言的技能它都很精通(或者在可见的未来里会很精通),比如归纳总结、翻译、书写文章、风格修正、翻译、润色、写代码等等。因而,从事这些工作的劳动者,如果不能掌握将ChatGPT作为助手的技能,也许将会成为最早期被机器取代的人。
概而言之,ChatGPT是超级工具,不是超级智能,它不会替代人类,而是在升级行业。它将极大降低创意和执行门槛,与人类相辅相成。
全球最大广告集团WPP首席执行官说:抢走你工作的从不是AI,而是其他掌握AI工具的人。
AI发展那么多年,那为什么ChatGPT能够成为AI赛道的黑马?

归根结底,源于对数据的“利用”。
当前,人工智能重大研究方向就是NLP任务(自然语言处理),也就是机器要读懂人类语言。而NLP任务(自然语言处理)有两大方向,一个方向是谷歌的双向(BERT)技术,另一个方向就是OpenAI的自回归(GPT)技术。
早在2018年6月,OpenAI公司提出初代GPT模型。同年10月,谷歌公司公布了自己的BERT模型,大幅度刷新了自然语言处理领域几乎所有最优记录,从此开启了预训练大模型时代。
在此后的4年时间里,预训练语言模型如 BERT 和 GPT(GPT-1和GPT-2,这些ChatGPT的前身),已成为当前自然语言处理领域的主流技术趋势。这些模型参数从3亿到1.75万亿不等,也因此被称作大语言模型(Large Language Model)。
而这些预训练大模型的本质是在使用更大的模型、更多的数据去找到对人类更好的、更通用的“语言模型”。也正是因此,包括BERT和GPT在内的大语言模型,在预训练过程中其实就已经获得了相当数量的词汇、句法和语义知识,仅仅只需要少量标记数据对模型细化,就可以完成各种各样的自然语言处理任务。

通过挖掘“数据”的价值,去赋予场景生态,这种类似的桥段是不是和“预言机”十分相似呢?只不过,ChatGPT仍属于Web2.0时代的产物,仍然具有一定的局限性。
如果说,ChatGPT、AIGC则完全无视你的主权,无所顾忌地抓取全球数据进行训练,最后制造出一个属于自己的“超级大脑”。那么,区块链技术的原教旨价值是“去中心化”,希望打破这种垄断,并重构一种新的分布式网络,让普通人重新拥有自己的数据主权。
预言机:链接数据桥梁
提及到区块链,想必大多数人想的是比特币、以太坊,再不济就是炒币、挖矿、DeFi、NFT,以及一些靠概念包装的GameFi、SocailFi等Web3.0赋能场景。但是,如何将数据“AI”化,也就是让“区块链”读懂现实世界的预言,并加于场景生态赋能化。预言机,便显得举足轻重,犹如当下的ChatGPT。
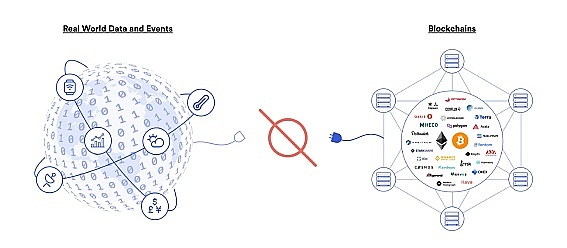
我们都知道预言机和区块链的关系非常密切。在区块链中,智能合约可以执行各种操作,例如资金管理、数据存储等。然而,智能合约并不知道现实世界中发生的事件,这就需要预言机。因为预言机是连接现实世界和区块链的数据桥梁,可以将现实世界中发生的事件转化为可用于智能合约的数据。
简单来说,预言机能让确定的智能合约对不确定的外部世界做出“反应”。而ChatGPT不就是对访问的数据做出与之对应的“反应”?
其中,预言机的主要功能是获取并验证外部数据,并将其输入到区块链中。它们可以采用多种方式获取数据,例如API、传感器、网络爬虫等。在验证数据方面,预言机需要保证数据的真实性和准确性。
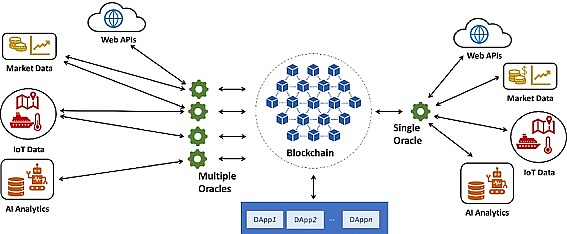
因此,预言机必须经过精心设计和测试,以确保数据的可靠性。这些验证过程可能包括数字签名、加密算法等。但预言机的发展也面临着一些挑战,其中最大的挑战之一是确保数据的可靠性。预言机需要获取大量数据,并对其进行验证。
如果把区块链比做一个“黑匣子”,那么预言机就是黑暗中的一束光,照亮着比特世界。
当然了,当前的区块链生态仍旧是发展的初级阶段,较之传统行业,除了在金融领域稍有建树外,其它地方仍稍显贫瘠。对于其数据的利用、调取、挖掘、分析,仍需很长一段时间去发展。
虽然市场涌现了不少像ChainLink、PlugChain、Oraclize、UMA、DIA 、API3这样的主流预言机公链,它们各在技术领域都有着各自的突破和创新,但细观生态发展、场景赋能、商业落地,依旧还有很长一段路要走。
这就像是,如果ChatGPT需要更智能,就需要更多、更大规模的数据训练。如果区块链世界需要更智能,就需要预言机的数据读取、传送、抓取更精准、更高效。
同时,在更去中心化问题上,单源 API 很容易被破解和操作,中心化预言机显得有些鸡肋。因此,像ChainLink、PlugChain、NEST等这种主打去中心化预言机网络的节点抓取数据的准确率更高些。因为他们的网络节点是则从多个来源拉取数据,通过数据聚合加权大大降低了数据的错误率。
顺便一提,在扩展性上,PlugChain凭借高吞吐量实现每秒处理十万笔交易的能力,且交易费用远低于其它公链。也因如此,它几乎消除了数据延迟,所以用户可以从中获得更准确的数据,使价格偏差和滑点变低。同样,在互操作性上,PlugChain已与 Ethereum、Cosmos、Polygon、Cardano、Avalanche、BSC 等主流公链兼容。在聚合式跨链上,它也有着极为出色的表现。
总之,预言机作为一座连接物理世界和区块世界的数据桥梁,具有重要的意义和潜力。它们不仅可以帮助智能合约更好地执行各种任务,并解决现实世界中的问题。同时,随着技术的进步和应用场景的扩大,预言机的未来将会更加广阔。
结语:最后,当我们去对比ChatGPT和预言机两者时不难发现一个核心点:两者存在的价值都是对“数据价值”的提炼,对“数据生态”的赋能,对“场景落地”的驱动。唯一不同的是,一个是在Web2.0,一个是在Web3.0。伴随着技术的日新月异,Web2.0和Web3.0的边界会越来越模糊,当预言机将物理世界的数据接入到比特世界中,以ChatGPT为代表的AI算力去不断挖掘“数据潜力”。
到那时,Web3.0的生态恐怕不再贫瘠、不再单调,和我们现实世界无异,那才是真正的Metaverse。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管92.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.26
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管79.20
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照82.07
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管60.90
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56