DMC——WEB3时代存储技术颠覆者简介



互联网快速发展的背后数据承载着巨大的递增负荷。根据国际数据公司( IDC ) 的监测数据显示,2013年全球大数据储量为4.3ZB (相当于47.24亿个1TB容量的移动硬盘),而2020年数据已增长至50ZB(1ZB=1024EB)。预计2025年将持续增长至163ZB,相当于每天全球会有2亿DVD数据的产生。海量数据的巨大储存需求的不断攀升激励着像Sia、Storj、Filecoin、Swarm、DMC等区块链分布式存储平台飞速发展起来,它们利用区块链去中心化分布式存储网络透明、平等协作的优势,激励更多的存储资源加入去中心化分布式存储网络中,刺激数据存储市场的多样性发展。
在为数不多的Web3.0数据存储探索者中,DMC(Datamall coin)作为Decentralized Storage Exchange Network的重要组成部分,将成为全球去中心化存储交易市场的冲锋者,致力于打破各个去中心化存储服务市场间的藩篱,构筑去中心化存储服务的安全数据存储桥梁。为Web3.0搭造一个自由、安全、高效的数据存储的基础建设。
总体架构
Datamallchain(DMC)去中心化存储的核心改进是撮合交易,但其实它在存储技术上的改进体渗入到存储流程的每一个环节。DMC倡导真实的存储,期望构建良性发展的去中心化交易市场,而真实存储需要区块链智能合约的验证来保证。在DMC用户在达成交易合约后,用户在此阶段可通过点对点传输存储数据,同时可向旷工随时发起存储挑战来验证旷工是否拥有真实的存储能力。存储挑战的智能合约通过验证方、服务方、和公证方的角色分工经历四个阶段来共同完成。
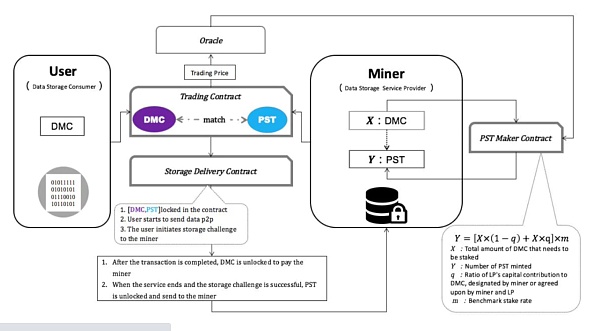
底层核心
DMC核心底层是基于CYFS开源协议进行开发,CYFS是下一代去中心化技术,通过对Web基础协议(TCP/IP+DNS+HTTP)的升级,实现了Web3的完全去中心化。 它具有颠覆性的架构设计,每个人都携带自己的OOD(Owner Online Device),形成一个真正去中心化的网络。
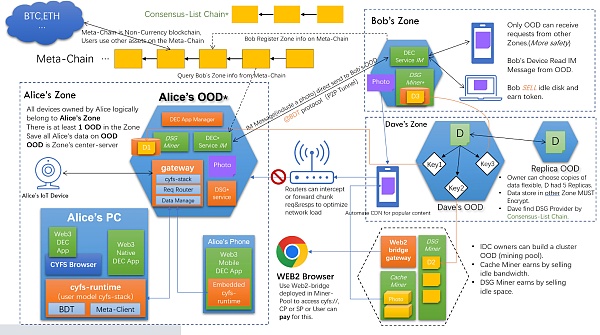
CYFS详细介绍自比特币于2008年发明以来,去中心化系统已经发展了14年多。如果说BTC是第一代去中心化系统,给人类带来了去中心化的思想,那么以太坊就是第二代。从最早的ICO到现在的DeFi,以太坊成功实现了金融的去中心化,带来了Web3的繁荣。看来人类很快就会实现Web2.0的革命。
但是,如果你冷静地看,你会发现NFT文件仍然存储在中心化的数据库中;DAO项目终于变成了“**Fi”;各种Web3应用程序本身仍然是中心化的Web2 Apps,并没有真正被公众使用。
根本原因在于区块链本身存在技术瓶颈,无法托管Web3 Apps。如果我们要Web3,就必须在基础设施技术上有所突破。
因此,CYFS团队从2016年开始就一直在努力开发新一代的去中心化基础设施技术。这比做一个需要克服很多技术挑战的应用要困难得多。但CYFS团队相信这样的新技术是Web3的基础,值得他们为之奋斗。经过多年的研发,他们终于可以自豪地宣布,他们已经解决了所有的技术难题,为您带来了全新的下一代Web3技术——CYFS。

CYFS如何构建Web3
Web3的核心是web的完全去中心化,让我们看看CYFS能做什么:
您的数据就是您的资产
在Web2中,所有用户数据都属于应用运营者,而在CYFS中,你产生的所有数据,文本、图片、评论、聊天记录、代码提交等,都是NFT,都是你的资产。您拥有它们并可以从中获利。
自由发布您的内容
在Web2中发布的内容可以随时被应用运营者删除,这是完全不可靠的。在CYFS中,您可以使用面向内容的、不可变的cyfs://来发布您的内容,并让其他人无延迟地访问它。该过程是完全去中心化的,没有人可以删除或限制您的内容。通过这种方式,CYFS保证了每个人在网络上平等发布内容的权利。
内容是跨应用的
Web2以应用程序为中心,而CYFS通过cyfs://以内容为中心。您的内容只要发布一次,所有CYFS应用都可以引用。这样,我们就实现了Tim Berners-Lee在1998年提出的“Semantic Web as web3”的想法。语义Web将重塑Web的底层逻辑。
自由运行您的应用程序
CYFS上的应用程序也是完全去中心化的。您的应用程序与您的数据一样,仅在您的控制之下,其他人无法关闭或更改功能。开发者有发布和更新应用的权利,用户有永久使用的权利。
自由出售您的存储空间
在CYFS中,计算资源也是去中心化的。您可以自由出售您的备用存储空间,让其他人备份他们的数据并从中获利。
完全去中心化的DAO应用
现在的DAO项目都是Web2应用+区块链,并不是真正的Web3。在CYFS中,可以构建完全去中心化的DAO应用程序,无需中心化服务器。
CYFS技术核心
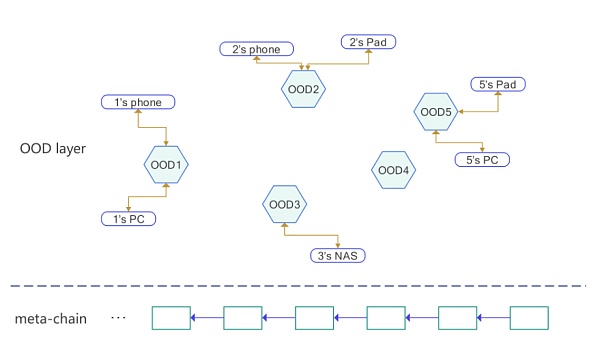
OOD最关键的创新之一是允许每个用户以自己的OOD(Owner Online Service)进入CYFS网络,这是去中心化的根本保证。OOD可以存储您的数据并为您进行计算。你用你的私钥控制它,通过这种方式,你真正拥有你的数据和你的应用程序。此外,我们在CYFS中有一个称为元链的区块链。结构如下:
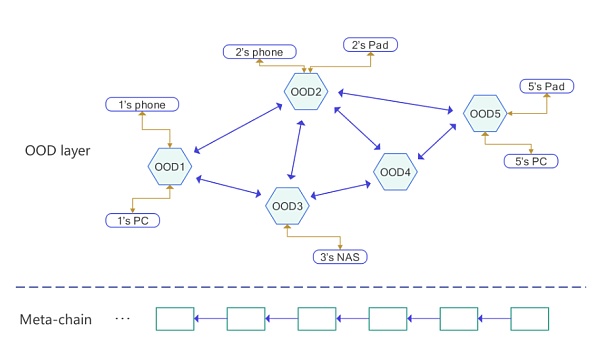
区块链作为DNS
我们使用区块链作为DNS而不是DHT的另一个关键创新。现在市场上的去中心化存储项目都使用了DHT(比如IPFS),但是在实践中是行不通的。DHT最本质的问题是一次检索需要数百个节点参与,没有激励网络就无法正常运行。另外,检索时间太长。
所以CYFS创造性地用区块链来做DNS。cyfs链接包含两段,第一段是你的device ID(你的OOD的唯一标识),第二段是数据的object ID(数据的Hash值)。
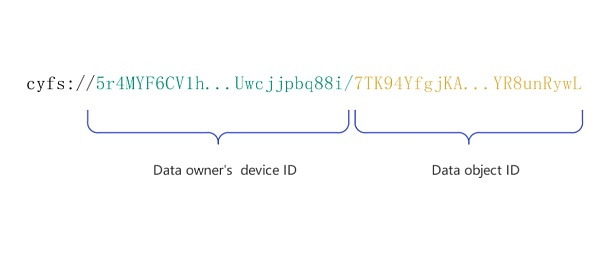
那么只要你在元链上发布“'你的设备ID':'你的OOD的最新信息'”,其他人就可以通过设备ID从元链上获取,并连接到你的OOD上请求数据。问题解决了!整个过程只需要一次请求,和中心化应用一样的延迟,没有人可以干涉。只要您确保您的OOD在线,任何人都可以看到您的内容。
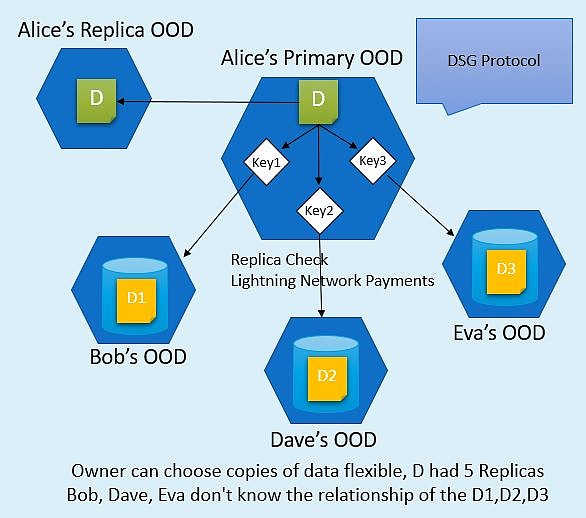
DSG协议
如果担心单个OOD存在数据丢失的风险,可以使用多OOD集群对数据进行多次备份。另外,您可以使用DSG协议支付一定的费用,对其他用户OOD上的重要数据进行加密备份。DSG协议可以保护双方的权益,让每个人都可以自由买卖存储资源。只要你付出足够的代价,你的cyfs链接永远不会404。
IPFS和Filecoin的缺点
IPFS的理念
IPFS的设计是每个人都可以自由运行自己的IPFS对等节点,组成P2P网络。您的数据存储在您的对等点上,并且可以被其他对等点自愿备份。每个数据在全网都有唯一的CID。只要知道CID,就可以从网络中检索数据,实现了数据的去中心化存储和检索。其具体运行机制如下:
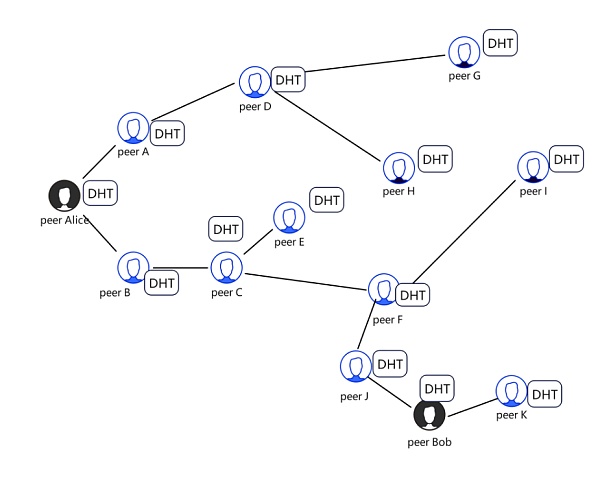
分布式哈希表
每个节点维护自己的分布式哈希表,它维护着一小部分节点的地址信息和网络中“提供者记录”的一小部分数据。“provider record”就是记录哪个节点有某个数据,比如“Alice有CID_D这个数据”。IPFS的整体架构如图所示:
数据存储过程
当Alice peer存储数据D时,她需要检索网络中距离该数据“最近”的m个peer(m一般为20),并请求它们在自己的节点中保存提供者记录“Alice has CID_D data” DHT。计算peer和CID_D之间“距离”的算法使用的是Kademlia算法。检索过程是,Alice首先从自己的DHT中找到与数据D“最接近”的K个peer,并请求他们保存记录。如果这些peer能在自己的DHT中找到比自己“更近”的peer,就会推荐给Alice,然后她再去请求这些“更近”的peer。这样,经过多轮请求,最终可以找到距离最近的peer,并存储记录。
数据检索过程
如果Bob想通过CID_D获取网络中的数据D,他需要找到距离CID_D“最近”的m个peer之一,并得到提供者记录“Alice has CID_D data”,然后知道Alice有数据并向她请求数据.计算“距离”和检索对等点的算法与数据存储过程相同。
缺点
这个系统看起来不错,但是它有一个致命的缺陷,就是这个网络中没有激励,也就是说每个人都需要为他人提供负收益的服务。比如DHT的维护,响应别人的检索请求会消耗巨大的带宽,为别人存储提供者的记录和数据会消耗大量的存储空间。这些都是需要成本的,但是这些东西跟自己没有关系,也没有什么好处。我相信大多数人都不想做这样的事情。IPFS Docs 也承认IPFS不能保证检索到的数据。

因此,IPFS基于DHT的去中心化检索方案只能在实验室环境下运行良好。一旦大量数据存储在IPFS上,它肯定会崩溃。
然后再说说FileCoin。很多人认为FileCoin是IPFS鼓励同行行为的激励层。然而事实并非如此。FileCoin用于在IPFS数据丢失的情况下为这些数据提供长期备份,而IPFS用于分散检索数据。FileCoin和IPFS是两个独立的网络。
另外,FileCoin的激励模式也存在问题。FileCoin的理念是存储的数据越多,存储的时间越长,奖励的FIL就越多。那么对于矿工来说,存储自己的垃圾数据不是比存储真实的用户数据更划算吗?因此,FileCoin虽然号称存储了大量数据,但几乎都是所有矿工都知道的垃圾数据。而且,一旦FIL价格大幅下跌,矿工也不愿意提供存储。如果用户真的在FileCoin上保存数据,很可能会丢失。
客观的说,IPFS的想法是正确的。如果IPFS系统是可靠的,那么每个人都可以在IPFS上自由发布内容,并允许其他人以去中心化的方式访问它。但正因为不是,所以人们只能把IPFS当作噱头。例如,一些NFT项目将自己铸造的NFT文件存储在IPFS上,并向用户展示:“你看,你的NFT文件已经去中心化存储在IPFS上了,无法删除,可以永远存在了。” 但是,这种用法既无效也不是 IPFS的初衷。
CYFS的创新设计
CYFS采用创新的架构解决了IPFS的上述问题,实现了真正可行的去中心化存储基础设施。与IPFS的peer类似,我们也让用户运行自己的OOD(Owner Online Device),形成一个P2P网络。架构图如下:
激励措施
IPFS的根本缺陷在于没有设计激励机制。问题来了,这个激励机制应该怎么设计?这看起来很复杂,但让我们回到人类商业社会的基本原则,就会一目了然:“谁有需求,谁支付成本”。在去中心化存储系统中,即:“谁对数据的可靠存储和检索有需求,谁就应该为成本买单”。显然,只有数据的拥有者自然有这种需求。所以,现在的激励机制很明确,数据拥有者自己应该负责数据的存储和检索。如果这个过程需要依赖第三方,他们应该得到数据所有者的报酬。IPFS的数据检索涉及数百个随机对等点,
区块链作为DNS
了解激励机制的基本原理后,理解CYFS就很容易了。如果Alice想使用CYFS发布她的内容,她可以生成一个cyfs://链接来分享它。cyfs://和ipfs://的区别是ipfs://只有一段,就是数据的CID,而cyfs://有两段。一节是Alice的OOD的唯一设备ID,一节是数据的对象ID(类似于CID)。这种设计的目的是让数据检索者直接向数据所有者请求数据。
那么,问题就演变成了Bob如何用Alice的设备ID快速获取到Alice OOD在CYFS中的地址。我们创新性地使用区块链来替代DHT,在CYFS中称为元链。只要Alice在元链上发布她的OOD的最新地址,Bob就可以通过设备ID从元链上获取并连接到Alice的OOD。问题解决了!后面的过程和IPFS是一样的。Bob直接向Alice请求数据,并通过检查对象ID来证明该数据是原始数据。整个过程不能被其他人干扰,并且具有与Web2相同的性能,只要Alice确保她的OOD在线即可。
可靠的数据存储
很多人可能会问如果数据是存放在自己的OOD上,那OOD宕机数据丢失了怎么办?解决这个问题有两种方法,一种是使用多OOD来实现高可用,另一种是在别人的OOD上付费加密备份重要数据(防止别人窃取数据)只要你能重新运行你的OOD在任何地方,您都可以使用私钥取回您的数据。CYFS设计了DSG协议,提供了完整的服务证明方式,可以保护双方的利益。同时,DSG协议支持在其上建立去中心化的存储撮合市场,为存储资源提供合理的价格和更多的激励。
还有人可能会问:“我的OOD在线维护太麻烦了,有没有办法让我不用运行OOD就可以存储和检索我的数据?”IPFS同意这个观点,这就是为什么他们提供像pinata这样的集中式ping服务。但这与AWS S3 有何不同?这个解决方案很容易实现,但是我们首先要知道,数据去中心化的意义是什么?Web3数据去中心化的意义在于让用户真正拥有自己的数据。如果不是为了拥有,放在Web2应用上更方便。如果你想真正拥有你的数据,你必须控制你自己的存储设备。
海量数据分发
通常情况下,这些设计已经足够了,但是还有很多场景需要在短时间内大规模分发数据,比如社交网络中的大规模分发数据,在线多线程的大规模分发。群聊等。我们设计了BDT协议来帮助应用程序开发人员解决这个问题,同时具有良好的整体负载。BDT的核心思想是,你的内容对其他人越有价值,就会有越多的节点愿意自愿备份你的数据,帮助你打通链接。如果没有志愿者,你也可以付钱给他们来实现这一点。我们做了这么多工作,就是希望构建出真正能够替代Web2应用的Web3应用。
DMC的交易核心
阶段一:存储准备
1,验证方对原始数据进行分块计算出默克尔树Merkle Tree,然后将默克尔树树根发送给公证方,同时将原始数据发送给服务方;相对于 Filecoin进行封装的存储挑战,矿工需提交Filecoin封装证明和默克尔树树根Merkle Root,DMC有效的缩短了环节时间。
2,服务方根据验证方提供的原始数据进行分块计算默克尔树,然后将默克尔树树根发送给公证方;
3,公证方对验证方和服务方提交的默克尔树树根进行比对,确认服务方提交的默克尔树树根与验证方提交的一致,确认默克尔树树根有效;若不一致,则存储准备终止。
阶段二:存储证明
1,验证方发起随机存储挑战:随机提取一个数据块,发送随机数,ID给服务方;
2,服务方收到验证方发的存储挑战,需在限定时间内根据挑战要求进行应答,计算公式:hash(Block(H, ID)+随机数);
3,验证方收到服务方的应答,对验证方挑战的签名进行验证操作,验证成功,则视为服务方应答有效;若验证失败,则视为服务方应答无效,验证方可发起挑战公证;
4,若服务方未在限定时间内发送应答给验证方或拒绝应答,验证方可发起挑战公证。
阶段三:挑战公证
1,验证方发起随机存储挑战:随机提取一个数据块,加上当前时间戳,然后进行整体签名,发给公证方。计算公式:Sign(hash(Block(H, ID)+随机数)),同时发送随机数,ID;
2,验证方向公证方提起挑战公证后,服务方需在限定时间内根据挑战要求进行应答,计算公式:hash(Block(H, ID)+随机数);
3,公证方收到服务方的应答,对验证方挑战的签名进行验证操作,验证成功,则视为服务方应答有效;若验证失败,则视为服务方应答无效;
4,若服务方未在限定时间内发送应答给公证方或拒绝回答,则视为服务方应答无效;
5,若服务方认为验证方为无效挑战,可针对此次挑战向公证方发起仲裁。
阶段四:仲裁
1,服务方向公证方提出仲裁后,验证方需在指定时间内将指定数据块的原始数据和对应剪枝默克尔树提交给公证方;
2,若验证方未在指定时间内提交挑战证明,则视为验证挑战无效,说明验证方违约;
3,公证方验证原始默克尔树树根与验证方提交的剪枝默克尔树树根一致;若不一致,证明验证方挑战无效,说明验证方违约;
4,公证方对验证方提供的剪枝默克尔树进行验证;若不一致,证明验证方挑战无效,说明验证方违约;
5,公证方根据验证方所提供的指定原始数据块计算指定原始数据块的哈希,确认是否和剪枝默克尔树中对应叶子节点哈希一致;若不一致,证明验证方挑战无效,说明验证方违约;
6,公证方对验证方所提供的签名进行校验;若结果一致,证明验证方挑战有效,说明服务方应答无效;若对比结果不一致,证明验证方挑战无效,说明验证方违约。
结语
从技术看DMC未来,DMC拥有着完美的技术底层框架,有着高并发和优秀的弹性扩充方案等,是下一代WEB3存储技术的颠覆者,未来必将引领分布式存储的发展!
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管89.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47